
SOLID未分類 マルチコアCPUでのリアルタイムOS(連載10)
マルチコアCPUで動くリアルタイムOS。
これって、どんなイメージがあります?
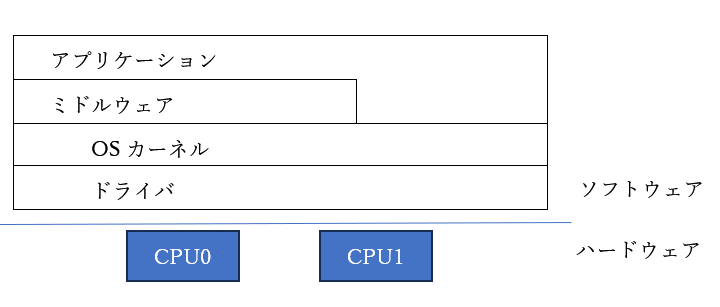
こういう感じのレイヤ図を良く見ますよね。
こういう図も。
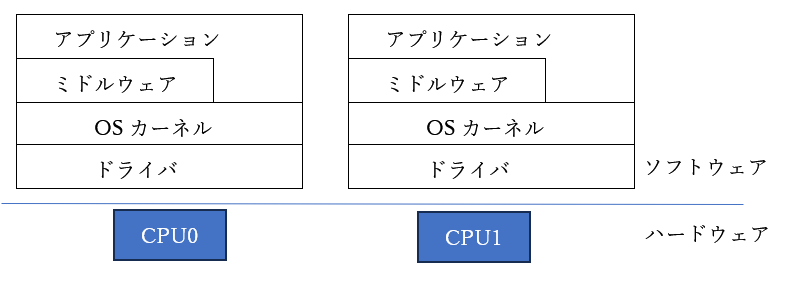
両方とも、マルチコアで動くリアルタイムOS?と思ってしまうのですが、よく見ると後者は一つのCPUで一つのOSになっています。
マルチコアの上で動くリアルタイムOS、というのは、2種類あります。
①複数のCPUコアの上で、一つのリアルタイムOSが動く
②それぞれのCPUコアの上でリアルタイムOSが動く
あるいはこれらの融合型も存在します。
SOLID-OSの言うところの「マルチコア対応リアルタイムOS」とはどちらでしょうか。
正解は①です。
この形です。
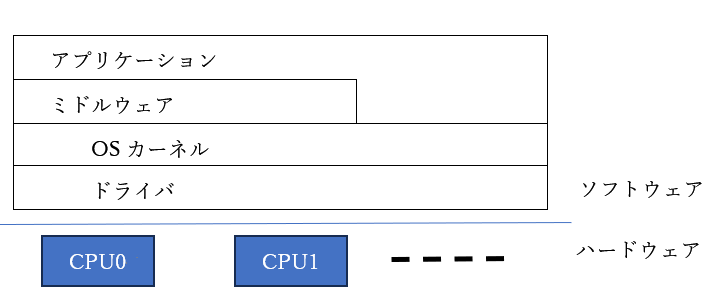
当然ですが、どんなCPUでもこの形に持っていけるわけではありません。
同じCPUコアで、かつ、すべてのCPUがメモリ空間を共有できることが必須です。
これはキャッシュも含めて、のお話です。
CPU毎に完全独立したキャッシュを持っていてもいいのですが、一貫性(コヒーレンシ)を保てる仕組みがないと、それぞれのCPUが見ているメモリデータが違ってきます。
SOLID-OSがサポートしているCortex-Aコアは、複数搭載でき、かつ、メモリの共有が完璧にできるCPUであるため、この形の実現が可能です。
こういうCPUコアのことを、対称型マルチプロセッサ(Symmetric Multiprocessor、SMP)、と言います。
そうでないけれどもマルチコアに対応しているCPUのことを、非対称型マルチプロセッサ(Asymmetric Multi-Processor / AMP)と言います。
違うCPUコアが複数入ってるよ、とか、キャッシュレベルではちょっと無理だけれども共有メモリはあるよ、というような類です。
SOLID-OSが採用しているTOPPERSの場合、各CPUはタスク単位で割りついています。
TOPPERSのマルチコア対応版(FMP)については以下URLで紹介されています。
一世代前(FMP/FMP3):https://www.toppers.jp/fmp-kernel.html
第三世代(FMP3):https://www.toppers.jp/fmp3-kernel.html
リアルタイムOSのカーネルも、タスクのうちの一つと考えることができます。
CPU0でブートアップした後は、各タスクがあらかじめ割り当てられたCPUの上で、普通のリアルタイムOSのタスクとして動作しています。
厳密には違うかもしれませんが、だいたいこんなイメージです。
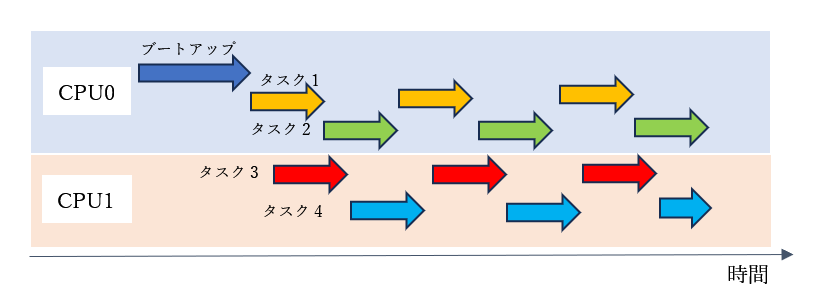
お待たせしました。
実際に見てみましょう。
前回に書いた、タスク&GPIO割り込み発生プログラムで試してみます。
実機は4コア搭載のRaspberry Pi4です。
Raspberry Pi4に搭載されているチップはBCM2711で、これは4つのCPUコアを搭載しています。
CPU0,1,2,3、です。
CPU3とCPU4はLinuxが動作していて、SOLID-OSはCPU0とCPU1の二つのCPU上で動作していますので、SOLID-OSとしては(物理的な)CPU0⇒(SOLIDが解釈する論理的な)CPU0、(物理的な)CPU1⇒(SOLIDが解釈する論理的な)CPU1と認識します。
# 8/8修正:CPU番号に間違いがあり修正しました。
さらにここでややこしい話をするのですが、TOPPERSではCPU番号を1からスタートします。
なので、TOPPERSのAPIとお話をする上では、それぞれCPU1, 2となるのです。
| BCM2711内CPU番号 | SOLID-OSが認識するCPU論理番号 | TOPPERS用番号 |
| CPU0 | CPU0 | CPU1 |
| CPU1 | CPU1 | CPU2 |
| CPU2 | - (Linuxが動作している) | - |
| CPU3 | - (Linuxが動作している) - | - |
以下、CPU番号について記載する場合は基本的に論理番号とします。
必要な時だけTOPPERSの番号を用います。
タスク生成時に、どのCPUで動作を行うかを割りつけます。
さらに、どのCPUで動作可能とするかについても指定します。
後述の、「タスクの引っ越し」の際に、引っ越し先となり得るCPUをあらかじめ指定する、という意味です。
こちらのURLに説明があります。
https://solid.kmckk.com/SOLID/doc/latest/os/kernel/kernel_config.html#c.TOPPERS.FMP3.task_initialization_block.iprcid
上記URLから抜粋します。
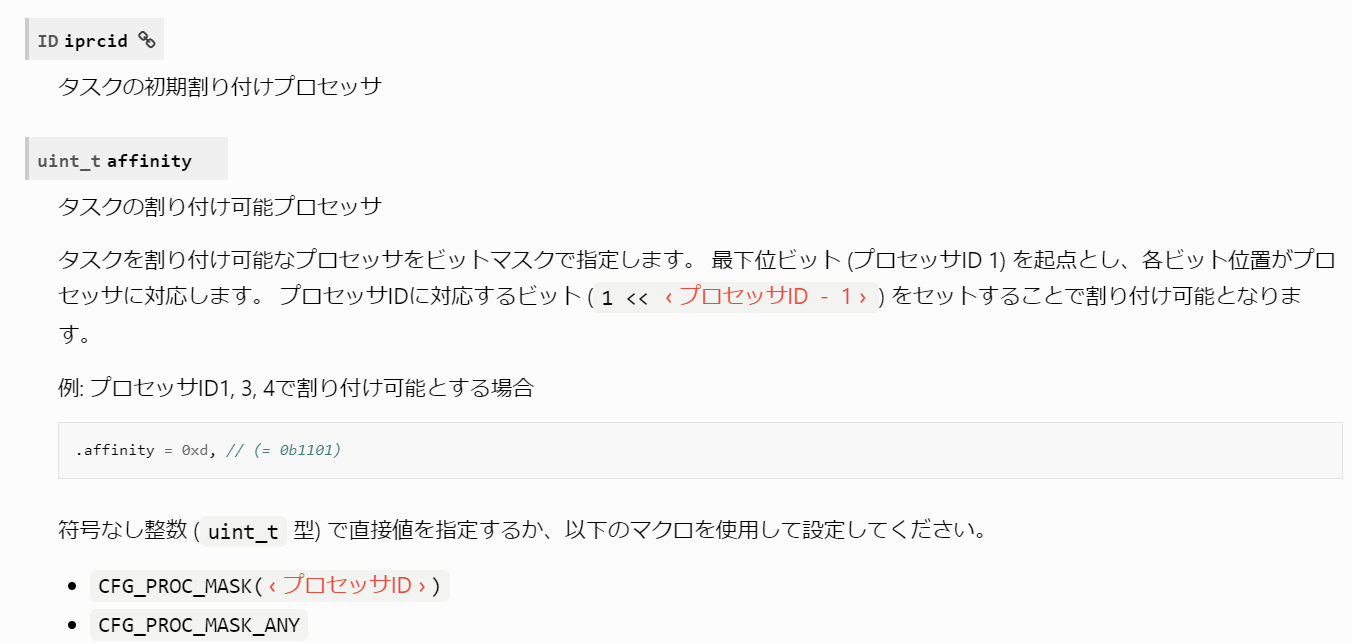
ここで前回作成したプログラムを見てみましょう。
// タスク動的生成のための情報設定
tsk1.tskatr = TA_NULL;
tsk1.task = test_task1;
tsk1.itskpri = MID_PRIORITY;
tsk1.stksz = STACK_SIZE;
tsk1.stk = NULL; // スタックはカーネルが自動的に割り当てる(SOLIDのスタックフェンスが有効)
tsk1.iprcid = 1;
tsk1.affinity = UINT_MAX;
// タスク動的生成のための情報設定
tsk2.tskatr = TA_NULL;
tsk2.task = test_task2;
tsk2.itskpri = MID_PRIORITY;
tsk2.stksz = STACK_SIZE;
tsk2.stk = NULL; // スタックはカーネルが自動的に割り当てる(SOLIDのスタックフェンスが有効)
tsk2.iprcid = 2;
tsk2.affinity = UINT_MAX;
すなわち、
タスク“test_task1”:
1番目のCPUで動作します。すなわちCPU0です。
後から割り付けを変更することができるCPUはすべてです。
タスク“test_task2”:
2番目のCPUで動作します。すなわちCPU1です。実際にはCPU4です。
後から割り付けを変更することができるCPUはすべてです。
# 8/8修正:CPU番号に間違いがあり修正しました。
となっていることがわかります。
では、動かしてみましょう。
タスク“test_task2”の途中、タスク“test_task1”からのイベントを受け取った後にブレークをしてみました。
タスク“test_task1”は、タスク“test_task2”からのイベントを待っているところです。
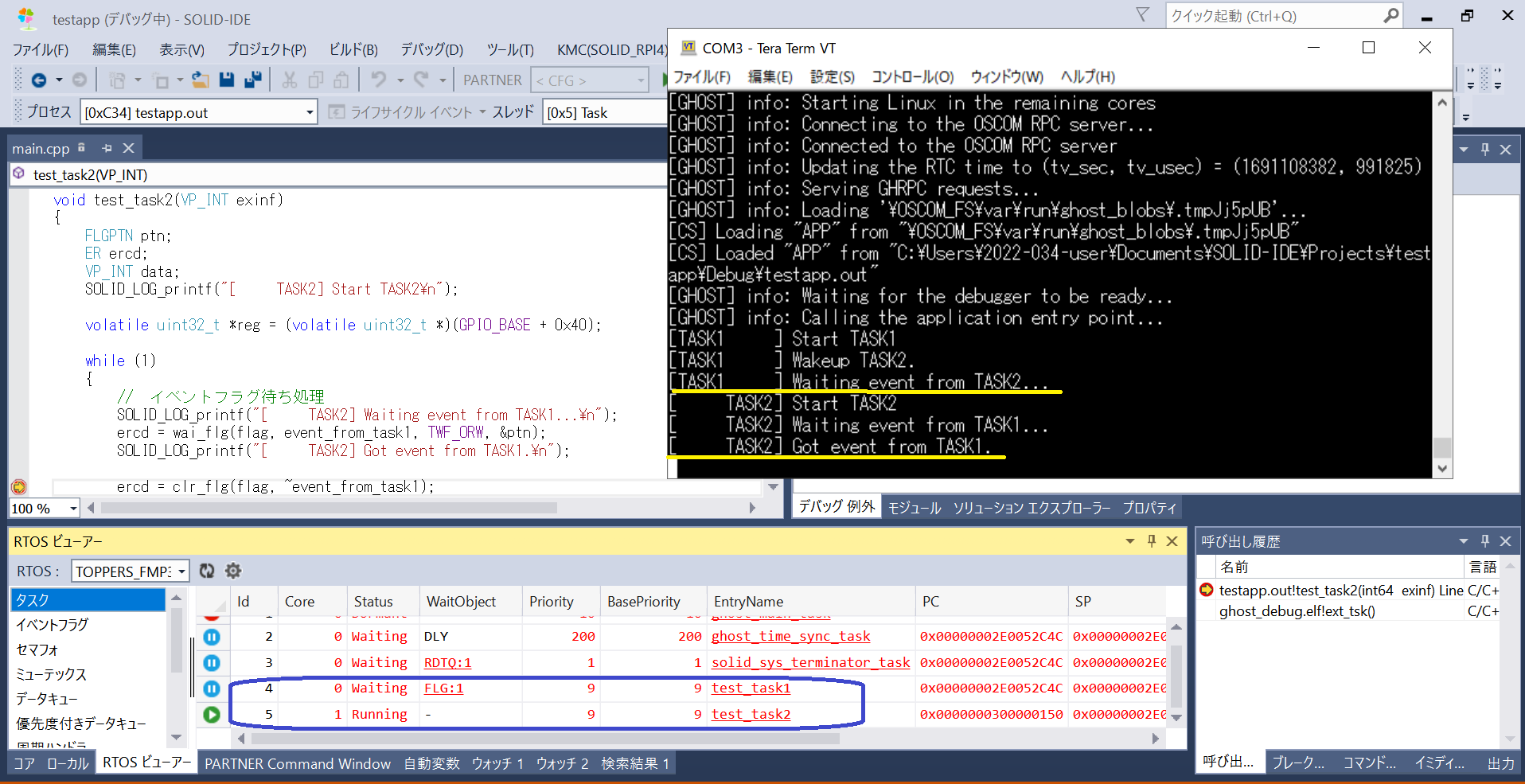
上記図の下部分、青く囲んだところが、RTOSビュワーです。
タスクID=4がタスク“test_task1”、タスクID=5がタスク“test_task2”です。
ここに、各タスクの状態が表示されています。
Core列を見ると、
“test_task1”はCore0(すなわちCPU0)
“test_task2”はCore1(すなわちCPU1)
に割ついている事が分かります。
そして、イベントも正しく発行&受け取りができていますね。
割り込みハンドラ登録用構造体を登録する際にコールするAPIとして、マルチコア対応の登録用APIをコールします。
マルチコア対応の登録用APIについては、以下URLに記載されています。
http://solid.kmckk.com/doc/skit/current/os/cs/intc.html#smpapi
前回のソースコードは、マルチコア対応の登録用APIをコールしていませんでしたので、今回変更してみます。
void gpioint_init()
{
// ① 割り込みハンドラ登録用構造体を作成
g_handler.intno = 145;
g_handler.priority = 10;
g_handler.config = 0b10; // SPI, エッジトリガ
g_handler.func = gpioint_handler;
g_handler.param = NULL;
//割り込み対象のCPUコアを指定する場合は以下のマルチコア用APIを使用する。
int target_processor = 1;
int ret = SOLID_INTC_RegisterWithTargetProcess(&g_handler, 1 << target_processor);
ret = SOLID_INTC_EnableM(g_handler.intno);
// ② 登録
// int ret = SOLID_INTC_Register(&g_handler);
// ③ 有効化
// ret = SOLID_INTC_Enable(g_handler.intno);
}
分かりやすいように、割り込みハンドラに、動作中のCPU番号を取得するコードを入れてみます。
int cpuid = SOLID_SMP_GetCpuId();
SOLID_LOG_printf("Button was pressed! CPU Core = %d\n", cpuid);
ちなみに、SOLID-OSでは、このようにマルチコア時に便利なAPIが準備されています。
上記のCPU番号取得API含め、以下URLに説明があります。
http://solid.kmckk.com/doc/skit/current/os/cs/smp.html
このURL冒頭に記載されている通り、これらのAPIを使用するためには、
#include "solid_smp.h"
が必要ですので、追加します。
では、動かしてみましょう。
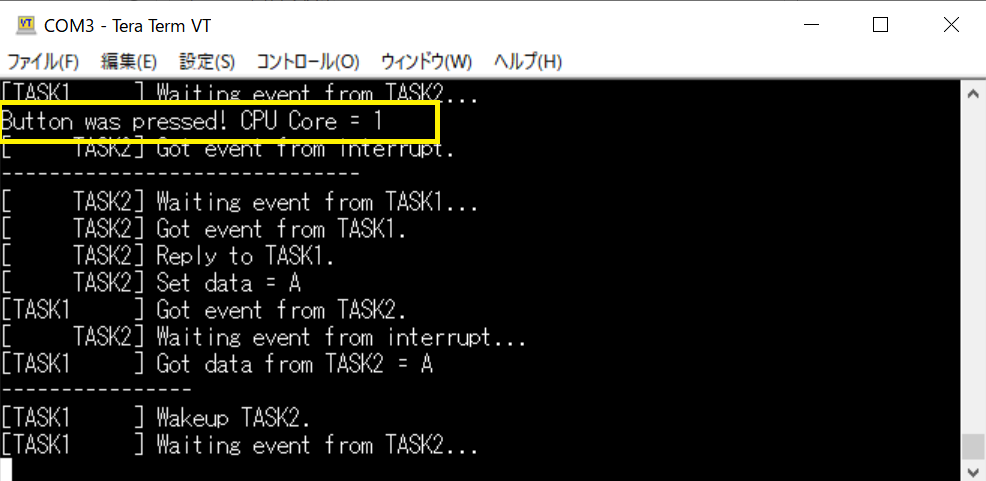
割り込みハンドラはCPU1で実行されていることがわかります。
次は、タスクの引っ越しを試してみます。
引っ越しをさせるためのAPIは
mig_tsk(ID tskid, ID prcid)
です。
tskidで指定したタスクの割付けCPUを,prcidで指定したCPUに変更します。
これはTOPPERSのAPIです。
詳細は「TOPPERS第3世代カーネル(ITRON系)統合仕様書」に記載されています。
https://www.toppers.jp/docs/tech/tgki_spec-360.pdf
ところで2点注意事項があります。
このAPI、現在動作中のCPUで動作しているタスクで行う必要があります。
すなわち、
・現在動作中のCPU上で動作
・タスク
である必要があります。
割り込みハンドラ等にはおけません。
では、プログラムを変更していきます。
今回は、起動後に
“test_task1”はCore0(すなわちCPU0)
“test_task2”はCore0(すなわちCPU0)
で動作させるようにします。
そして、途中から“test_task2”をCPU1に、引っ越しさせてみましょう。
という事で、“test_task2”生成する際に設定する、タスク情報を記した構造体を以下のようにします。
// タスク動的生成のための情報設定
tsk2.tskatr = TA_NULL;
tsk2.task = test_task2;
tsk2.itskpri = MID_PRIORITY;
tsk2.stksz = STACK_SIZE;
tsk2.stk = NULL; // スタックはカーネルが自動的に割り当てる(SOLIDのスタックフェンスが有効)
tsk2.iprcid = 1;
tsk2.affinity = UINT_MAX;
ここでaffinityメンバに着目してください。
これは、タスクを割り付け可能なプロセッサをビットマスクで指定しているものです。
affinityメンバはUNIT_MAXになっていますね。
全フラグが ’1’ いう事なので、どのコアでもOK!です。
(といっても、ここではコア数2つですが。)
という事で、CPU0で動作している“test_task2”を途中からCPU1に引っ越しさせても大丈夫です。
そしてmig_tsk()、“test_task1”に置いてみましょう。
mig_tsk()に指定する引っ越し先CPUはCPU1(Core1)ですが、TOPPERSのAPIに渡すため、2番目のCPUコアとなり’2’と指定します。
void test_task1(VP_INT exinf)
{
FLGPTN ptn;
ER ercd;
VP_INT data;
SOLID_LOG_printf("[TASK1 ] Start TASK1\n");
while (1)
{
// TASK2のCPUコアを0から1に引っ越しさせる
ercd = mig_tsk(5, 2);
// TASK2に向け、イベントフラグ設定
SOLID_LOG_printf("[TASK1 ] Wakeup TASK2.\n");
ercd = set_flg(flag, event_from_task1);
// TASK2からのイベントフラグ設定待ち処理
SOLID_LOG_printf("[TASK1 ] Waiting event from TASK2...\n");
ercd = wai_flg(flag, event_from_task2, TWF_ORW, &ptn);
SOLID_LOG_printf("[TASK1 ] Got event from TASK2.\n");
// データキューから'A'をセット
rcv_dtq(dtq, &data);
SOLID_LOG_printf("[TASK1 ] Got data from TASK2 = %c\n", data);
// TASK2から受けたイベントフラグ設定クリア
ercd = clr_flg(flag, ~event_from_task2);
dly_tsk(5000'000); //5sec
SOLID_LOG_printf("----------------\n");
}
return;
}
#ここでは”test_task2”のタスクIDは’5’だとわかっているものとします。
先程RTOSビュワーで見たので。。。
実際には、タスクIDを取得するコードを入れたりする必要があります。
さらに、せっかくなので、”test_task2”に、動作中のCPU番号を表示するコードを入れてみます。
void test_task2(VP_INT exinf)
{
FLGPTN ptn;
ER ercd;
VP_INT data;
int cpuid = SOLID_SMP_GetCpuId();
SOLID_LOG_printf("[ TASK2] Start TASK2 on CPU Core = %d\n", cpuid);
volatile uint32_t *reg = (volatile uint32_t *)(GPIO_BASE + 0x40);
while (1)
{
// イベントフラグ待ち処理
SOLID_LOG_printf("[ TASK2] Waiting event from TASK1...\n");
ercd = wai_flg(flag, event_from_task1, TWF_ORW, &ptn);
cpuid = SOLID_SMP_GetCpuId();
SOLID_LOG_printf("[ TASK2] Got event from TASK1. CPU Core = %d\n", cpuid);
ercd = clr_flg(flag, ~event_from_task1);
// イベントフラグセット
SOLID_LOG_printf("[ TASK2] Reply to TASK1.\n");
ercd = set_flg(flag, event_from_task2);
// データキューに'A'をセット
data = 'A';
SOLID_LOG_printf("[ TASK2] Set data = %c\n", data);
snd_dtq(dtq, data);
//dly_tsk(1000'000); //1sec
SOLID_LOG_printf("[ TASK2] Waiting event from interrupt...\n");
dly_tsk(100'000); //0.1sec待つ。上記printfが終わってからフラグを待つようにしたいため。
ercd = wai_flg(flag, event_from_interrupt, TWF_ORW, &ptn);
SOLID_LOG_printf("[ TASK2] Got event from interrupt.\n");
ercd = clr_flg(flag, ~event_from_interrupt);
cpuid = SOLID_SMP_GetCpuId();
SOLID_LOG_printf("[ TASK2] CPU Core = %d\n", cpuid);
SOLID_LOG_printf("------------------------------\n");
}
return;
}
では、実行してみます。
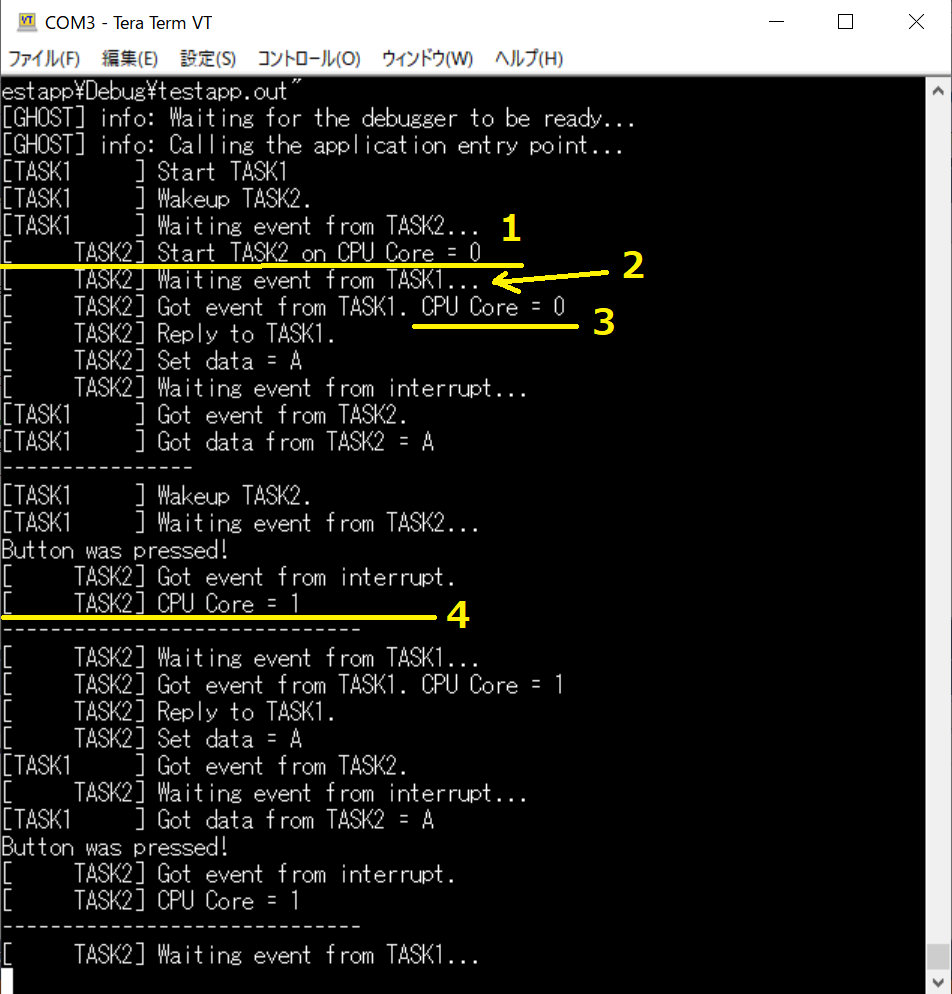
1:”test_task2”実行開始時点ではCPU番号は0です。
2:”test_task1”からイベント受信しました。
”test_task1”では、この直前に”test_task2”の実行CPUを1に引っ越しさせる操作をしました。
3:この時点ではまだ”test_task2”の実行CPUはCPU0のままです。
4:ここまでくると、”test_task2”の実行CPUはCPU1に変わっています。
無事、引っ越しできていますね。