
SOLID未分類 SOLID for Raspberry Pi 4 (連載6)
前回、ローカル変数名を適当にローワーキャメルケースでつけたところ、ビルド時におこられてしまいました。
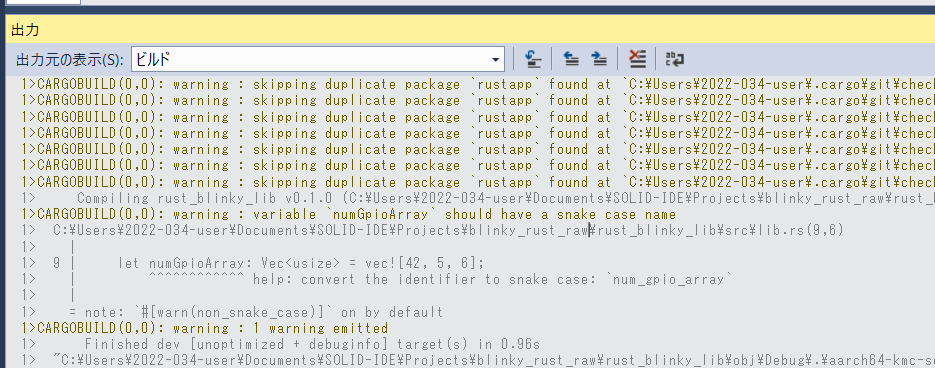
Rustでは、基本的な命名規則として、RFC 430という定義があります。
https://github.com/rust-lang/rfcs/blob/master/text/0430-finalizing-naming-conventions.md
命名規則表を抜粋します。
以下のように書かれています。
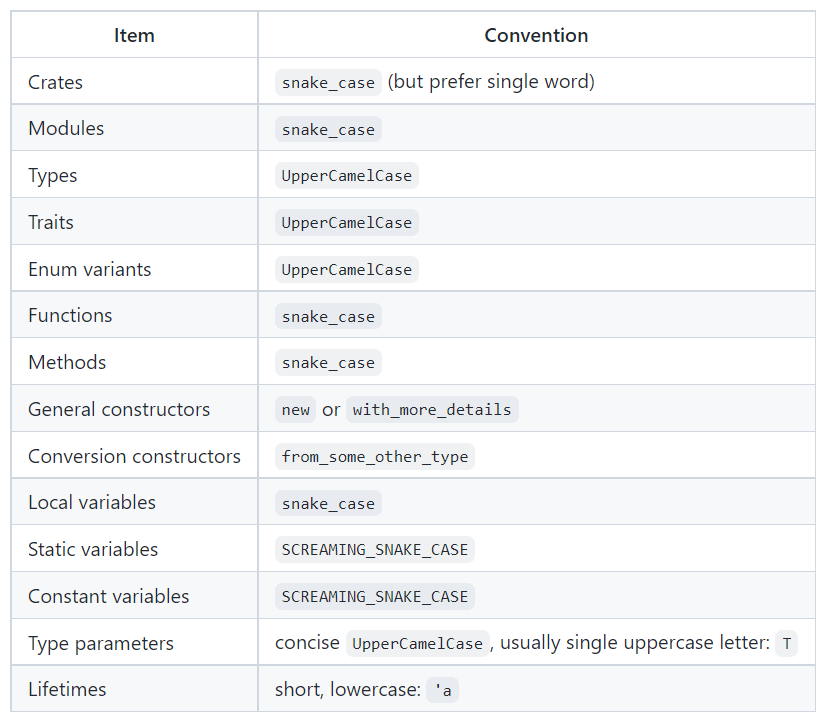
あれ?
ローワーキャメルケースがない。
[補足] アッパーキャメルケース:NumGpioArrayのように、単語の先頭が大文字。C言語では、どのシチュエーションで何を使うかは、ある程度決まってはいるものの、運用はチーム内で統一していればいいかな、というくらいの意識でした。
RustではRFC 430に従っていない変数名はWarningが出るんですね。
いや、でもこれは確かに。
ローカル変数って、ローワーキャメルケース好きとスネークケース好きがいますよね。
人が書いたプログラムを見て、あぁそーかキミはスネークケース君か、とか思いながら読んだり。(え?してません?)
ちゃんとプログラミング教室に通って教育された方ばかりじゃないので、いろんな書き方をする人がいます。筆者も独学派なので、あれ?というところで知識の欠落があったり。
命名規則をあまり深く考えず適当に書いていたので、もしかしたら今までものすごく恥ずかしいプログラムを書いていたかもしれない。。。
はい、これから気を付けます。
Warning、出してくれて助かりました。
重要な事に気が付けました。
C言語でプログラムを書く時にも、気をつけるようにしよう、と思った次第です。
C言語の場合、文字コードは、基本1バイトで表せるASCIIコード。
日本語を使う場合の文字コードはコンパイラによって異なりました。
少し前はWindows用Visual StudioだとだいたいシフトJIS, Linux用だとだいたいUTF-8、というように異なっていました。
Rustの場合、何もしなければ文字コードは常にUTF-8です。
試しに、外部エディタを使ってシフトJISで書いたlib.rsを、SOLID-IDEでビルドしてみたところ、エラーになりました。
2通り試したのですが、両方とも同様でした。
・コメントのみ日本語を含む場合
・ソースコードにも日本語を含む場合(println!マクロ内の文字列)

筆者としては、ここにはあまりひっかかるポイントはありませんでした。
Clang/LLVM コンパイラはUTF-8だし、GCCは変更できますが基本はUTF-8。
Visua Studioも今は基本的にUTF-8になっているようです。
これから作るソースコードであれば、文字コードとしてUTF-8を採用すればいいのではと思います。
シフトJISを扱わないといけない時というと、既存コードの保守の場合、でしょうか。
膨大にシフトJISコードのファイルがあるような場合、コンパチビリティを求めたい場合。
この場合、[u8] でシフトJISを扱うライブラリを探し、適用する、という方法をとることになります。
あと一点。、、
UTF-8なので、文字列操作関数が複雑になるのかなぁと漠然と思いました。
で、いい例が公式に載っていました。
https://doc.rust-lang.org/std/string/struct.String.html
let s = "hello";
// The following will not compile!
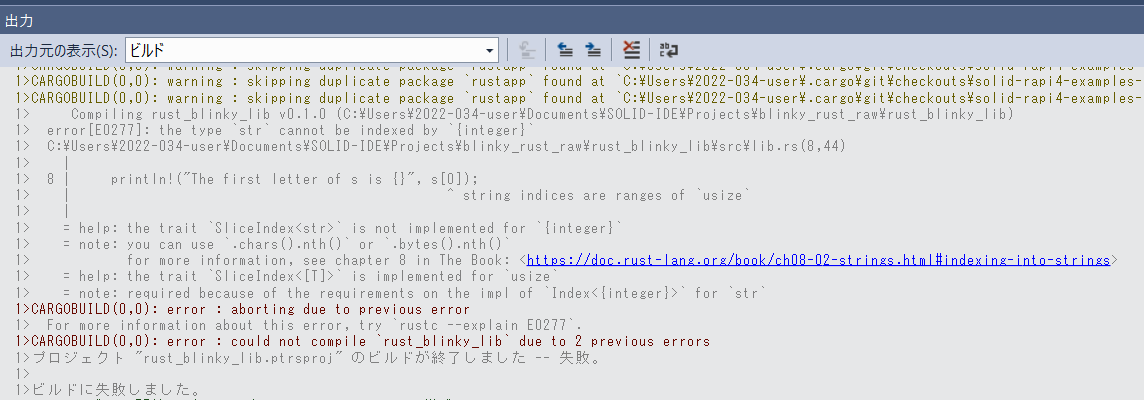
println!("The first letter of s is {}", s[0]);
これはエラーになります。
文字列sの1バイト目の数字はアルファベットで、1バイト文字なので’h’でしょうが、
UTF-8との事、常に1バイト文字である保証はない、という事です。
SOLID-IDEでも確認してみました。
エラーになりました。
1文字目を抽出したい場合は、以下のようになります。
let first_character = s.chars().nth(0);
C言語は文字列を扱う際、1バイトのASCIIコードが基本となっています。
一方、Rustでは1バイト文字もマルチバイト文字も同じように扱えるようになっている、すなわち、配列を意識せず、最初から文字列として扱うようになっているようです。
したがって、Rustでは文字列を操作するための、独自関数が存在します。
C#のSystem.String クラスのようで、これはありがたい機能ですね。
次は、構造体のデータのレイアウトについてみていきましょう。
struct AlignmentTest {
byte1: u8,
short1: u16,
long1: u32,
byte2: u8,
short2: u16,
long2: u32,
}
という構造体を定義します。
どのように配置されたかSOLID-IDEで見てみました。
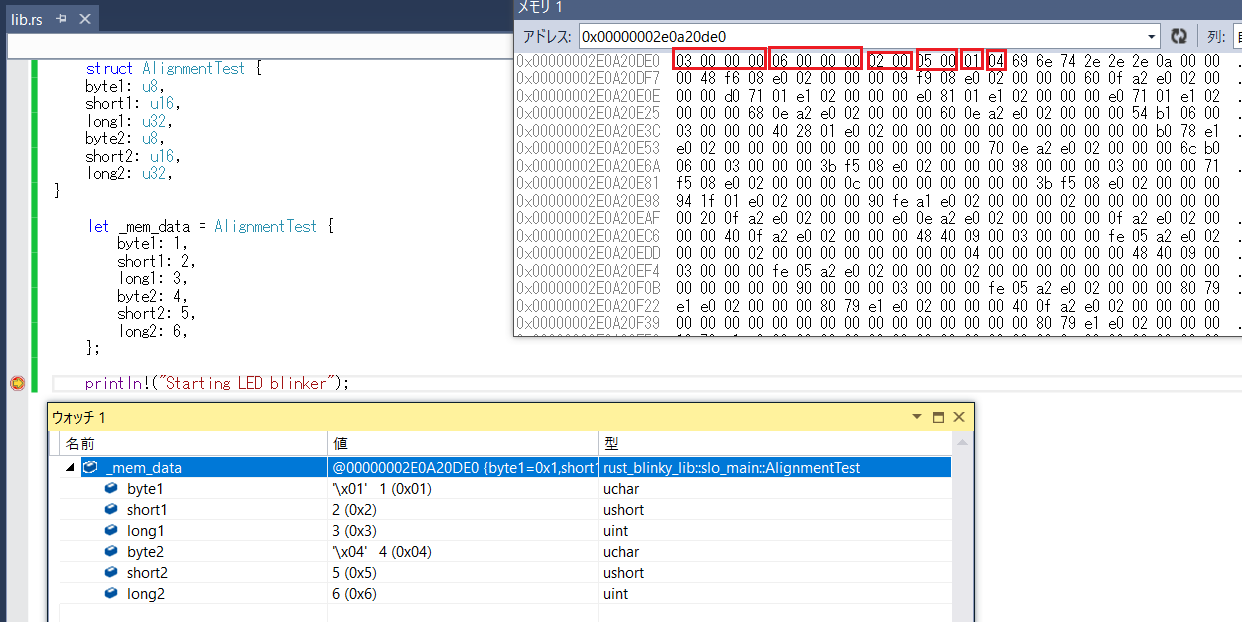
おっと、struct定義した位置と違っているではないですか!
u32, u32, u16, u16, u8, u8の順番になっています。
メモリ効率は良いかもしれませんが、組み込み用途で使うにはマズいです。
ハードウェアのI/O定義ができなくなってしまいます。
大丈夫、これに対処するためには、レイアウトを保証して欲しい旨をコンパイラに通知すればOKです。
structの定義に、#[repr(C)]を付ければ大丈夫です。
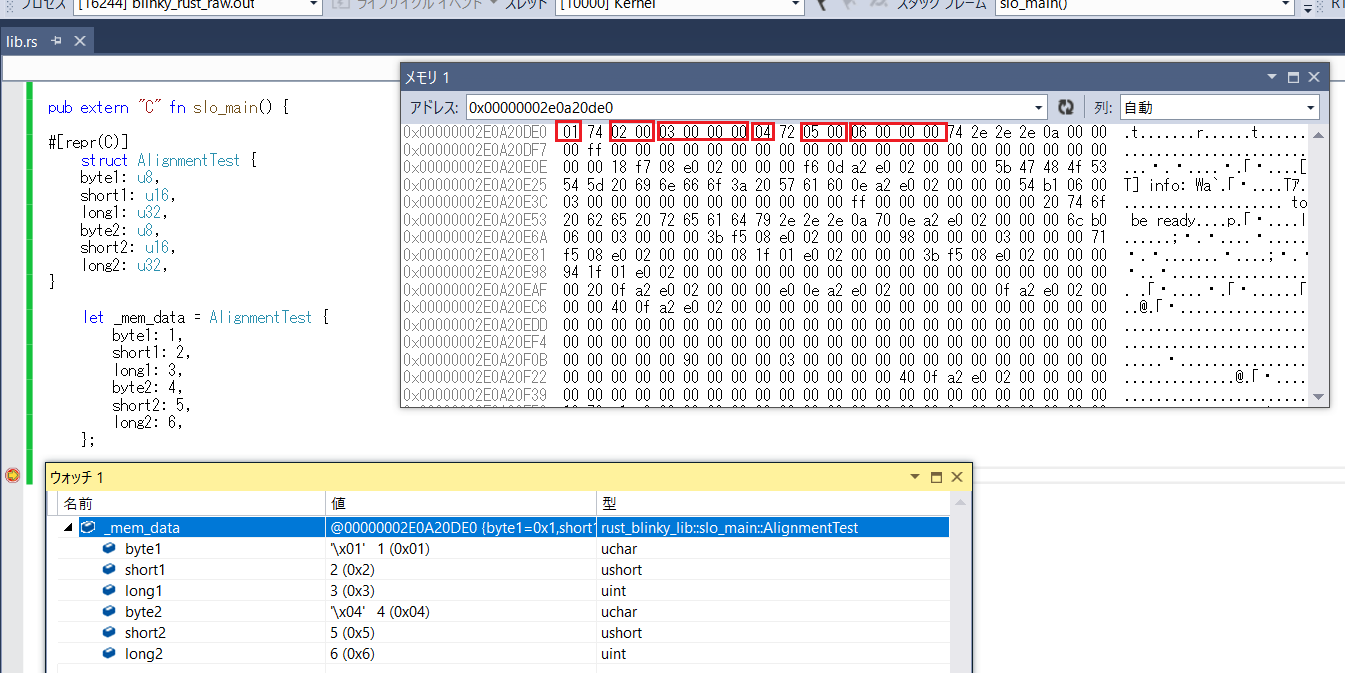
良かった。
struct定義通りに配置されました。
ちなみにアクセスサイズについても考慮されています。
short1とbyte1の間に、ダミーの1バイトが挿入されていることがわかります。
ハードウェアのI/O定義用構造体でなければ、メモリ効率を意識して自動で並べ替えてくれる事はありがたいですね。
I/Oの定義として使う時は、#[repr(C)]をつければOK。
その他、こまごまとした規則において、初期状態が安全な選択をするよう考慮されています。
初期化なしの場合ビルドエラーになります。
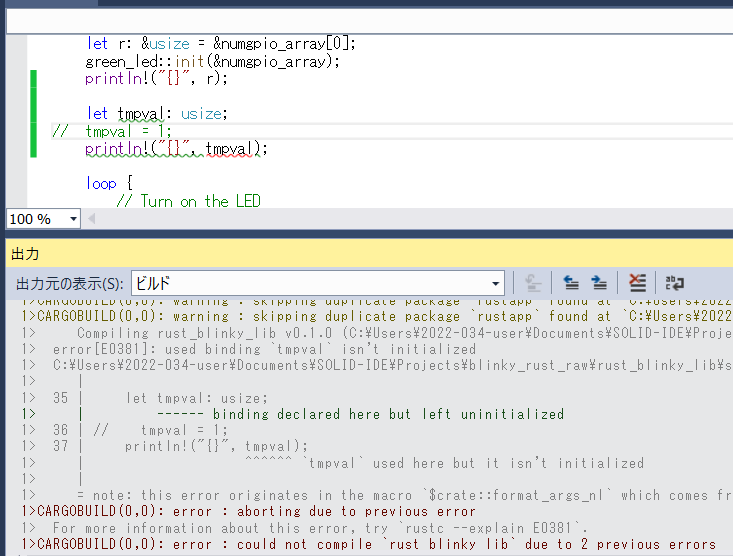
コメントアウトしている、//tmpval=1; を復活させれば大丈夫です。
公式に記述あります。
https://doc.rust-lang.org/std/mem/union.MaybeUninit.html
え?これって大きな配列も?
確保だけして、あとで値を入れる、をするにはMaybeUninitを使うという事ですね。
とりあえず0クリアしておけばいいのかな。。。
変数定義については、明示的にmutと記述し、可変の値であることを示さない限り、定数として扱われます。このため、値の変更ができません。
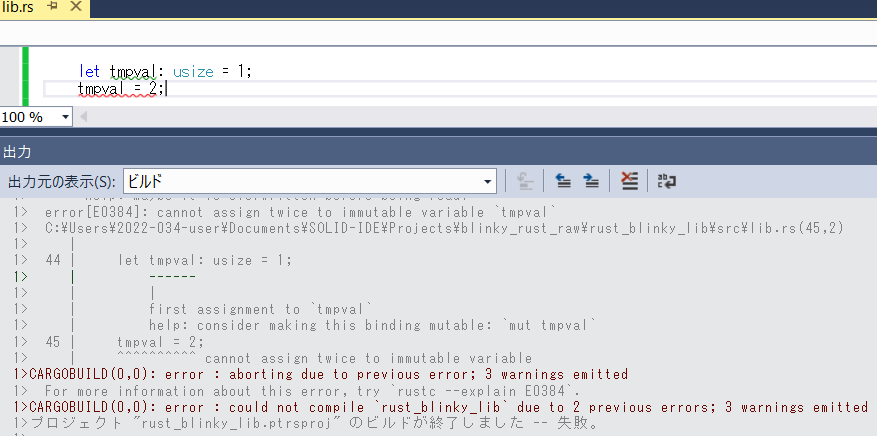
let mut tmpval: usize = 1;
とすれば、書けるようになります。
modを宣言することにより、モジュールという閉じた空間を設定することができます。
ここで定義された関数等が、他のモジュールからアクセスされる時には、pubを宣言してパブリック化しないといけません。
そうでない場合は、プライベート扱いとし、他からはアクセスが禁止されています。
C#の静的クラスのような概念でしょうか。
前回のLチカソースプログラムでは以下の部分です。
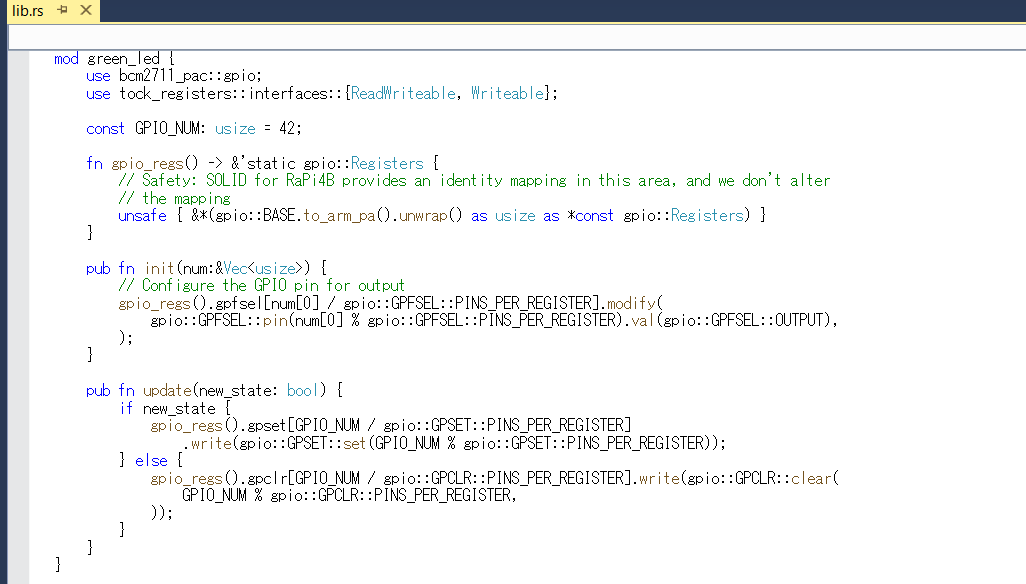
init関数とupdate関数をmainルーチンからコールできるよう、”pub” が指定されています。
switchという文法はありません。
代わりにmatch文といって、より強力な文法があります。
https://doc.rust-lang.org/rust-by-example/flow_control/match.html
match number {
// Match a single value
1 => println!("One!"),
// Match several values
2 | 3 | 5 | 7 | 11 => println!("This is a prime"),
// TODO ^ Try adding 13 to the list of prime values
// Match an inclusive range
13..=19 => println!("A teen"),
// Handle the rest of cases
_ => println!("Ain't special"),
// TODO ^ Try commenting out this catch-all arm
}
この部分ですが、
_ => println!("Ain't special"),
を削除するとビルドエラーとなります。
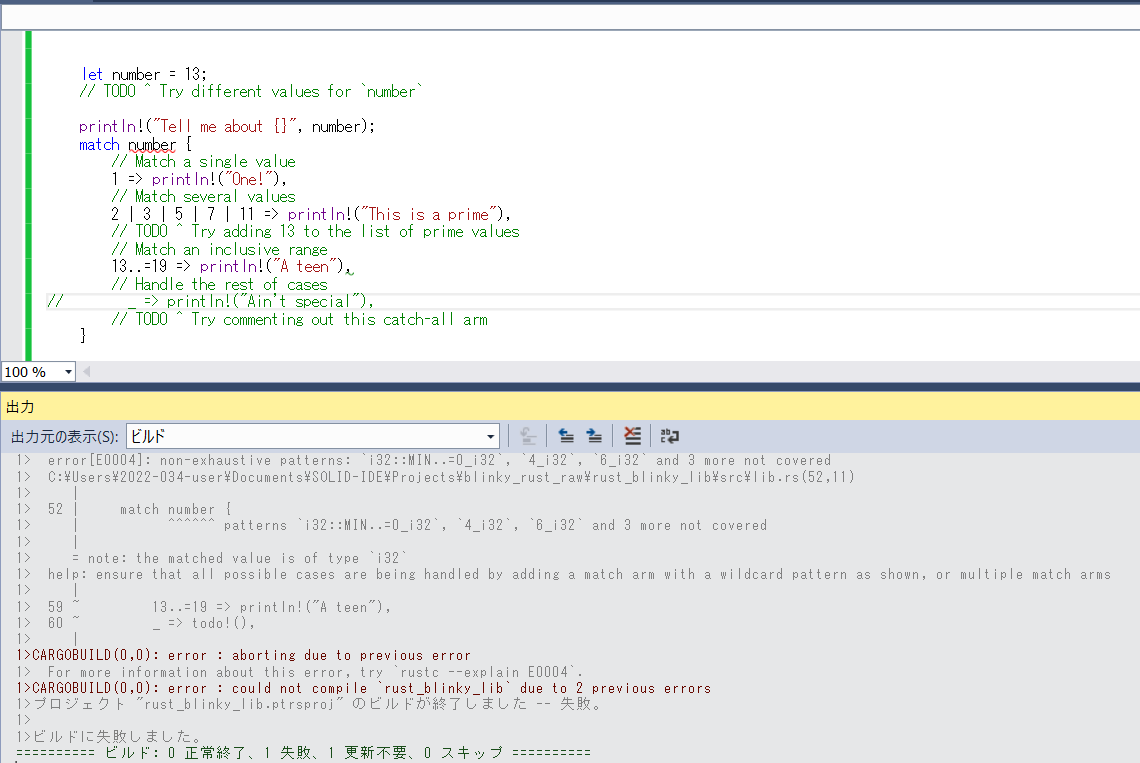
すべてのケースをハンドルできなきゃだめだ、と言われてしまいました。
<補足>
厳密には、rustのmatchは、すべてのパターンでの処理の記述が必要という事です。
defaultそのものが必要というわけでありません。
defaultそのものの記述が必要な場合が多いものの、enumなどで、全てのパターンを簡単に記述できる場合には、default的な構文無しのパターンもOK。
さらに、default無しで書かれていれば、enumの要素を増やした場合などでコンパイルエラーとなり修正ミスを防ぐ事ができます。
今まで見てきたように、Rustではいろいろと制約があり、難しいなぁ、面倒だなぁ、と感じることが多いです。
ですが、ここまで言語仕様でガチガチにされているのであれば、コーディング規則を頑張って作って、皆に徹底して、遵守して、協力的でないメンバーに溜息ついて、、、という苦労が要らなくなることになります。
時間がたち、チームが新しいメンバに代わって行ったときに、労力なくコードを引き継げる、持続性可能なソースコードという、まさかここでSDGsが出てくると思わなかったですが、非常に効率の良いシナリオではないでしょうか。
今回はここまで。
次回は「Cargoとは?」に触れてみたいと思います。